论文引用信息及相关资料
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is All you Need[J]. Neural Information Processing Systems,Neural Information Processing Systems, 2017.
[1706.03762] Attention Is All You Need (arxiv.org)
Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili
超强动画,一步一步深入浅出解释Transformer原理!_哔哩哔哩_bilibili
OpenAI ChatGPT(一):十分钟读懂 Transformer - 知乎 (zhihu.com)
【精选】图解Transformer | The Illustrated Transformer-CSDN博客
【精选】Transformer 结构详解:位置编码 | Transformer Architecture: The Positional Encoding-CSDN博客
贡献&核心
早在2017年就提出了Transformer这一架构的论文,至今已有94856次引用,深度学习领域的必读论文。这一架构最初在处理文本信息等机器翻译方面表现优秀,随着相关研究的不断推进和GPT等基于Transformer技术的落地,如今在整个NLP领域transformer都是当仁不让的top1架构。
- 首次提出完全基于自注意力机制的序列建模模型
- 通过多头注意力机制消除了由于CNN架构时序排列计算导致的低并行性,减少训练时间,同时加强了模型的记忆能力
摘要
本文介绍了一种基于注意力机制的新型神经网络模型——Transformer,可以用于序列转换问题,如机器翻译。与传统的基于循环神经网络和卷积神经网络的模型不同,Transformer完全依赖于注意力机制,消除了循环和卷积的使用,具有更高的并行性和更短的训练时间。文章详细介绍了Transformer的结构和训练方法,并在机器翻译和句法分析等任务上取得了优异的结果。
模型整体架构
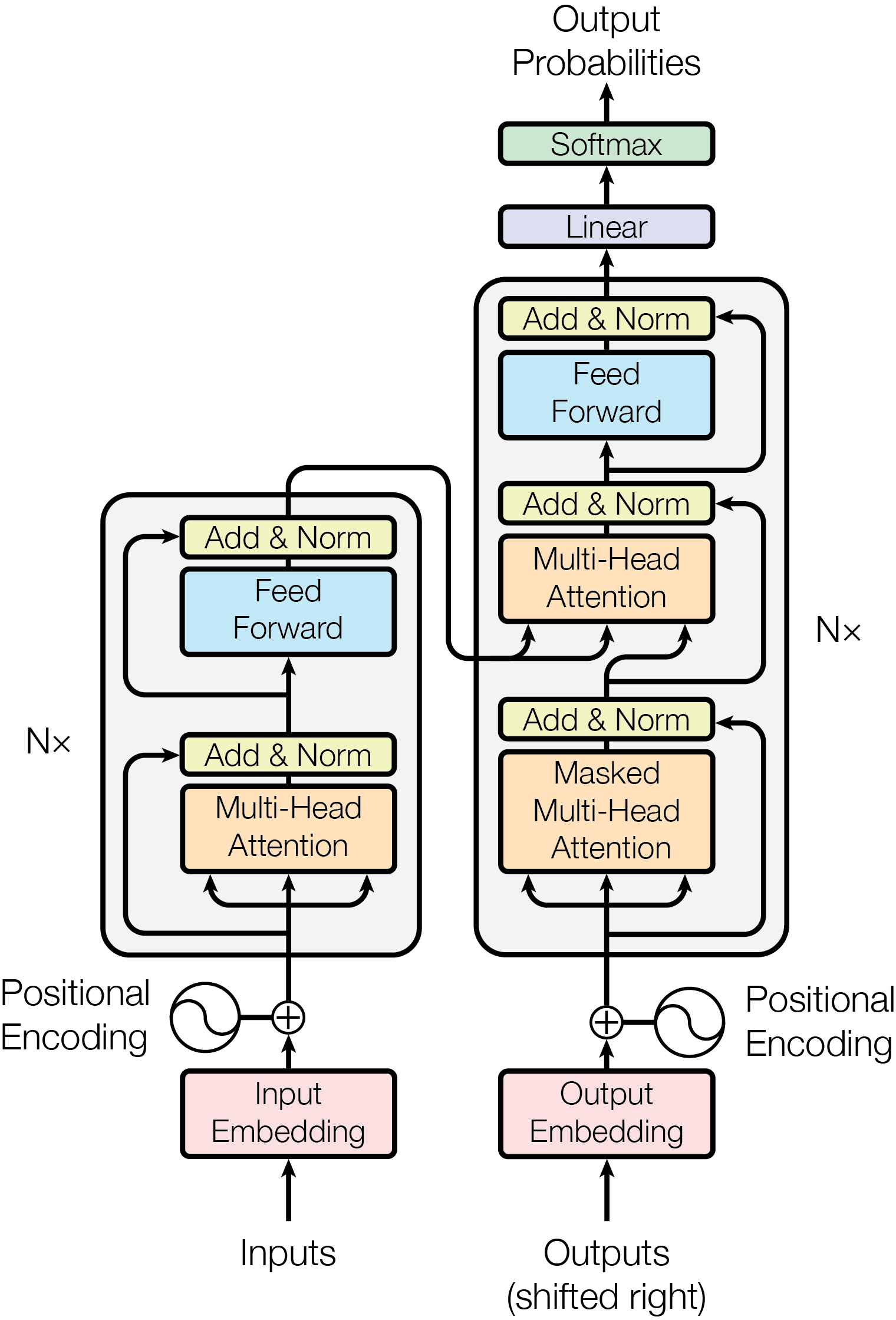
Embedding 嵌入向量
In/Output Embedding
常规的词-向量转换,通过word2vec等模型预训练得到
Positional Encoding
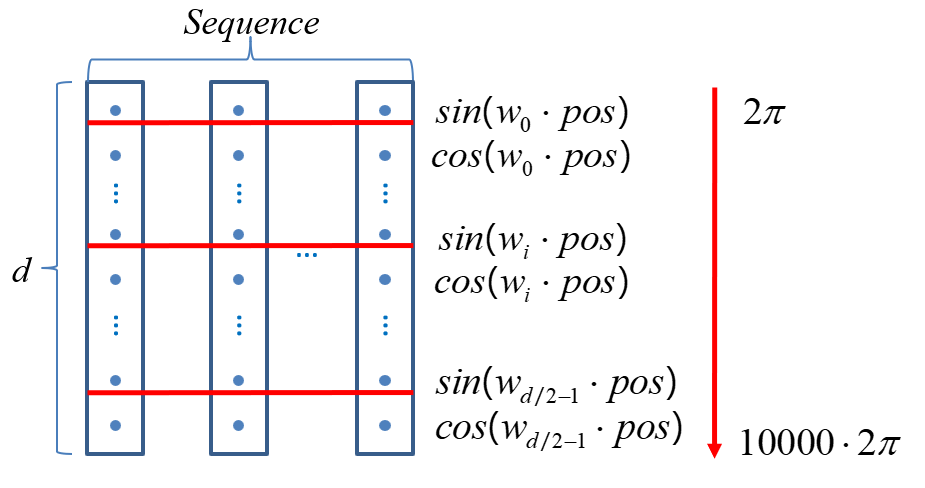
位置编码,**因为 Transformer不采用RNN结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于NLP来说非常重要。**所以Transformer中使用位置Embedding保存单词在序列中的相对或绝对位置。【精选】Transformer 结构详解:位置编码 | Transformer Architecture: The Positional Encoding-CSDN博客
这篇论文使用如下算法计算相对位置:

其中 pos 是位置,i 是维度
Add:Reidual Connection 残差连接
残差连接是一种在深度神经网络中的连接方式,主要用于解决深度网络训练中的梯度消失和梯度爆炸问题。其核心思想是引入一个短路连接,将网络中的输入层与输出层直接连接,使得网络在训练过程中能够更有效地传递信息和梯度。
残差链接的主要特点是在网络层之间添加一个跳跃连接,这个连接允许梯度在层间直接传递,从而增强了网络的学习能力。通过这种连接方式,神经网络可以更好地捕捉到输入数据中的局部特征和全局特征,提高模型的性能。
Normalization 归一化
将向量均值变为0,方差变为1,主要目的是在不同层之间稳定和优化梯度计算,减少训练过程中的波动,并提高模型的性能。
层归一化(Layer Normalization):层归一化应用于每个 Transformer 层之间。它的主要作用是使输入和输出数据具有相似的分布,从而在不同层之间进行更平稳的梯度计算。层归一化通过对输入数据进行缩放和偏移操作,将数据分布调整为均值为 0、标准差为 1 的正态分布。这样,每个层的输出都可以看作是具有相同分布的数据,有助于稳定训练过程。
批量归一化(Batch Normalization):批量归一化应用于每个训练样本之间。它的主要作用是规范化输入数据,减少内部协变量转移(internal covariate shift),从而在不同样本之间保持梯度的一致性。批量归一化通过对输入数据进行归一化操作,将数据分布调整为均值为 0、标准差为 1 的正态分布。
为什么Transformer架构使用LayerNormalization而不是更为常见的Batch Normalization?
答案是在变长序列的样本中LN抖动更少,且无需全局化
下图蓝色代表BN,黄色代表LN

对于小批量变长的样本(忽略填充值)使用batchNormalization计算均值方差时抖动会很大,同时由于其记录全局均值方差,碰到特异长度的样本时,预测效果可能会差
而layerNormalization只在样本内计算,不记录全局,相对稳定
Multi-Head Attention 多头注意力机制
Self-Attention 自注意力机制
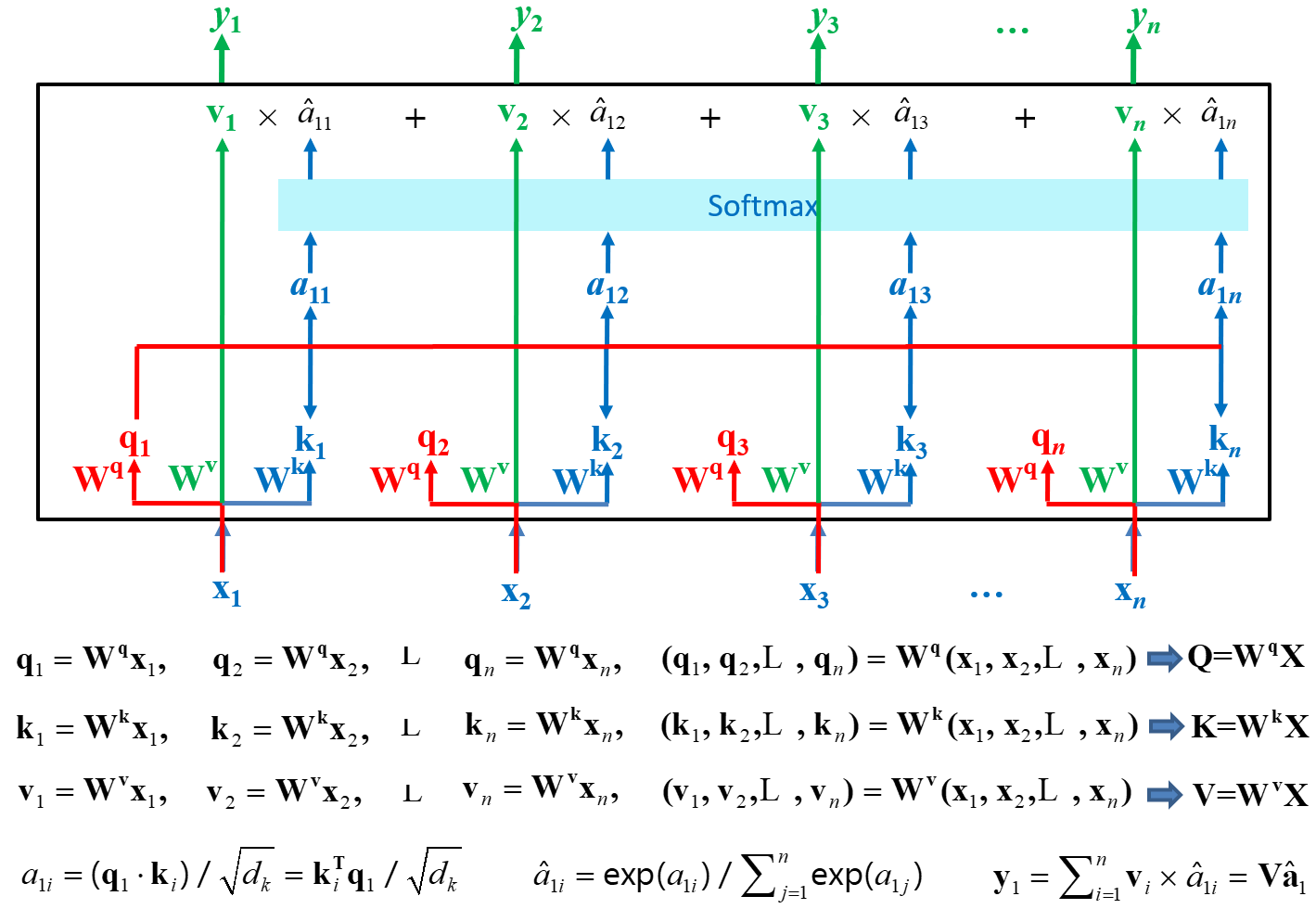
上图中小写字母为向量,大写字母为向量聚合的矩阵
输入矩阵X通过与三个不同的权重矩阵相乘获得Q(Query查询)K(Key键)V(Value值)三个矩阵
计算q与每个k的相似度获得a
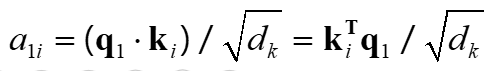
softmax化a获得总和为1的权重
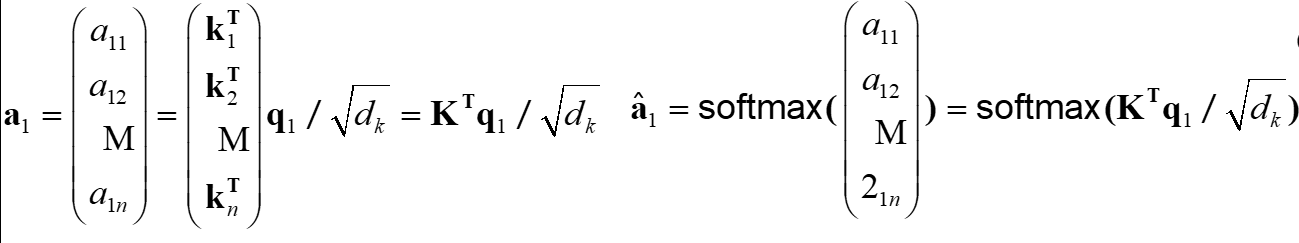
每个v乘以对应的权重得到一个最终的自注意力化向量
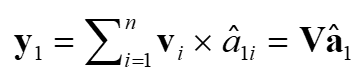
y聚合成为最终的Y,结果矩阵
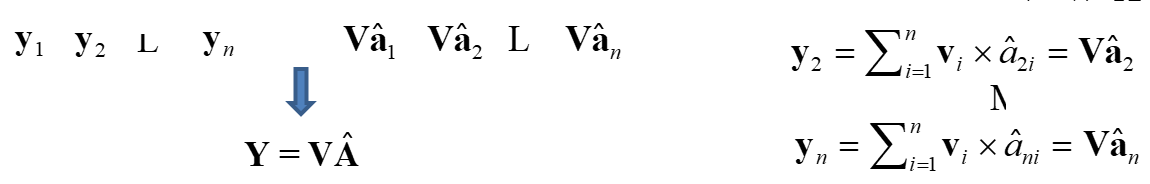
上述过程的矩阵化表述,Z为上文的Y:
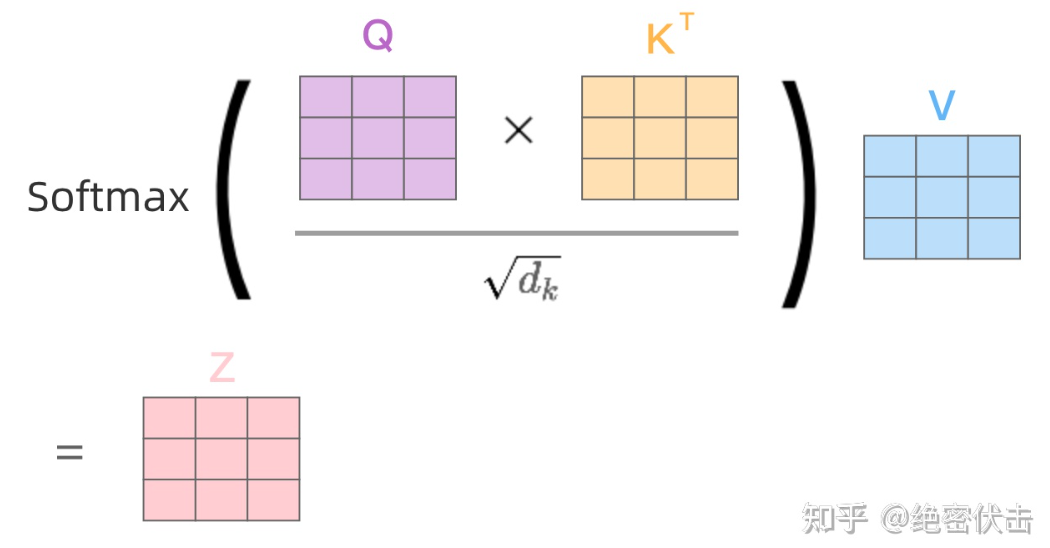
Multi-Head Attention 多头注意力
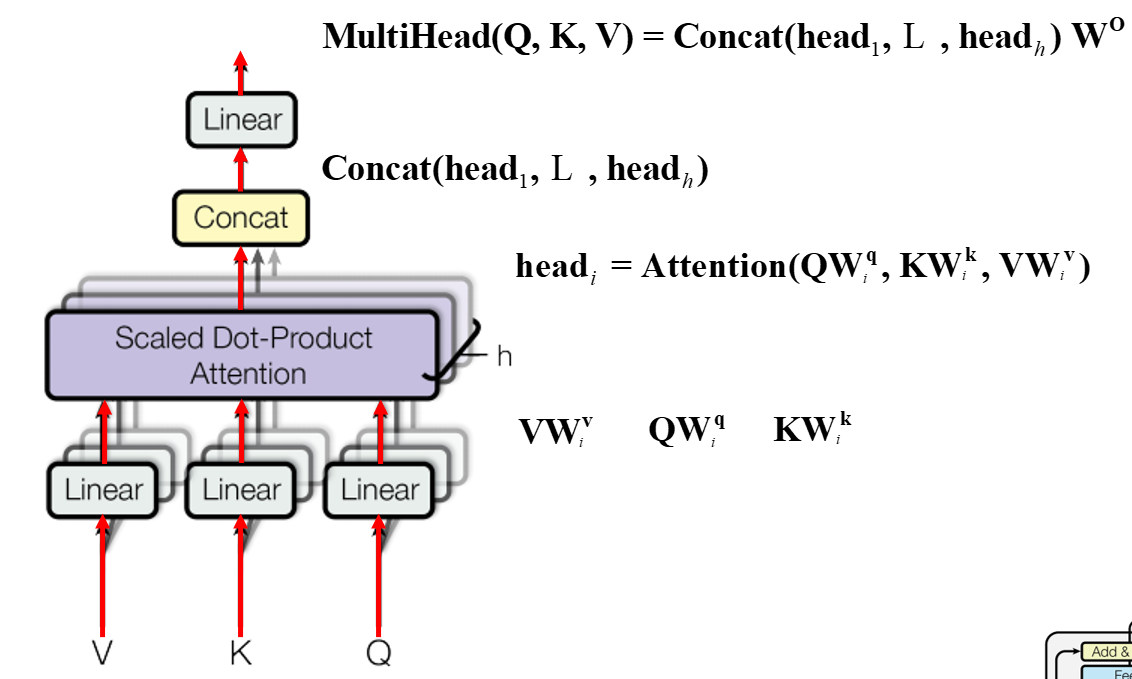
从上图可以看到Multi-Head Attention包含多个Self-Attention层,首先将输入 X 分别传递到 ℎ 个不同的Self-Attention中,计算得到 ℎ 个输出矩阵 Z ,以h=8为例。
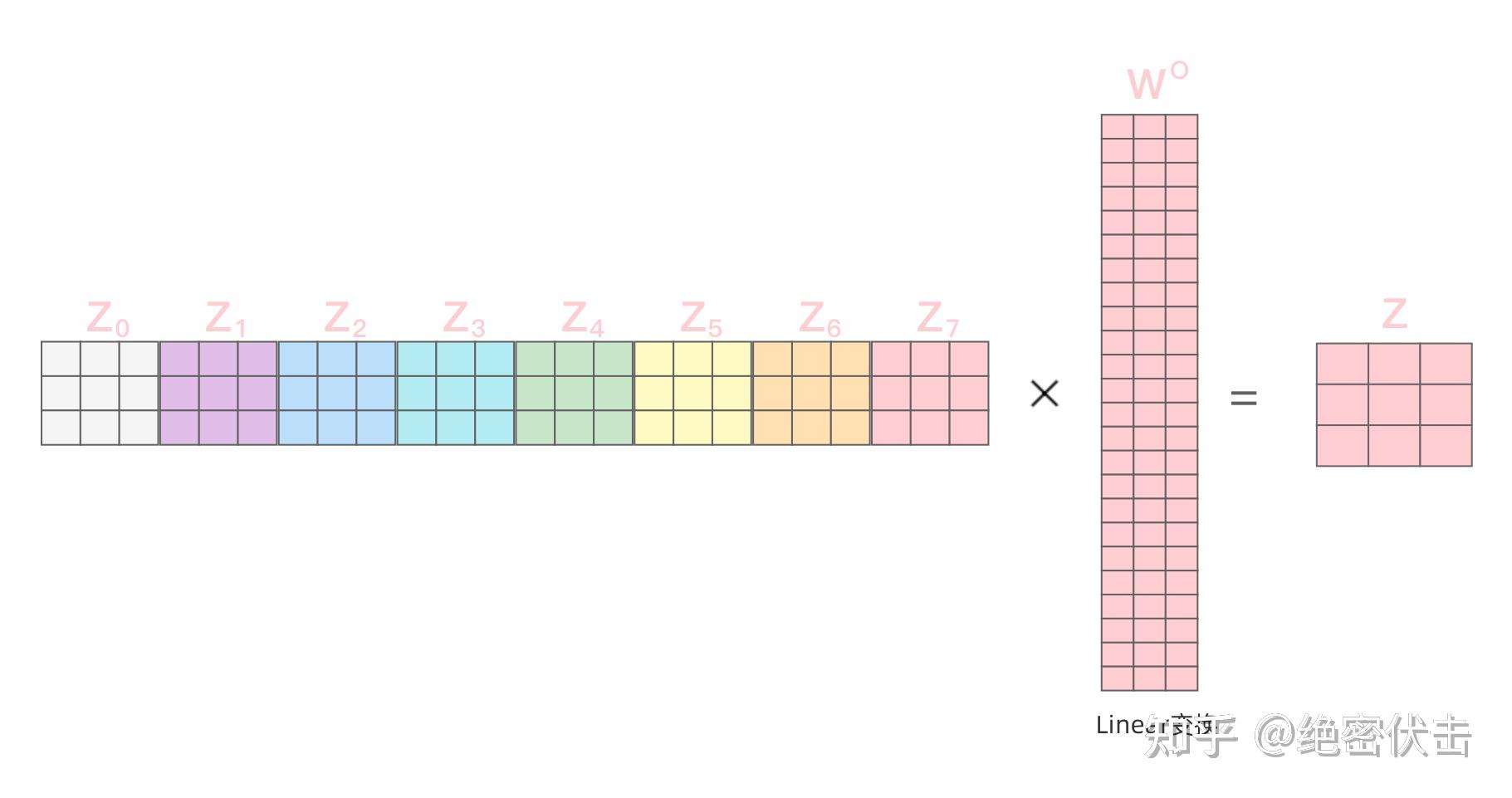
得到8个输出矩阵 Z0∼Z7 后,Multi-Head Attention将它们拼接在一起(Concat),然后传入一个Linear层,得到Multi-Head Attention最终的输出矩阵 Z。
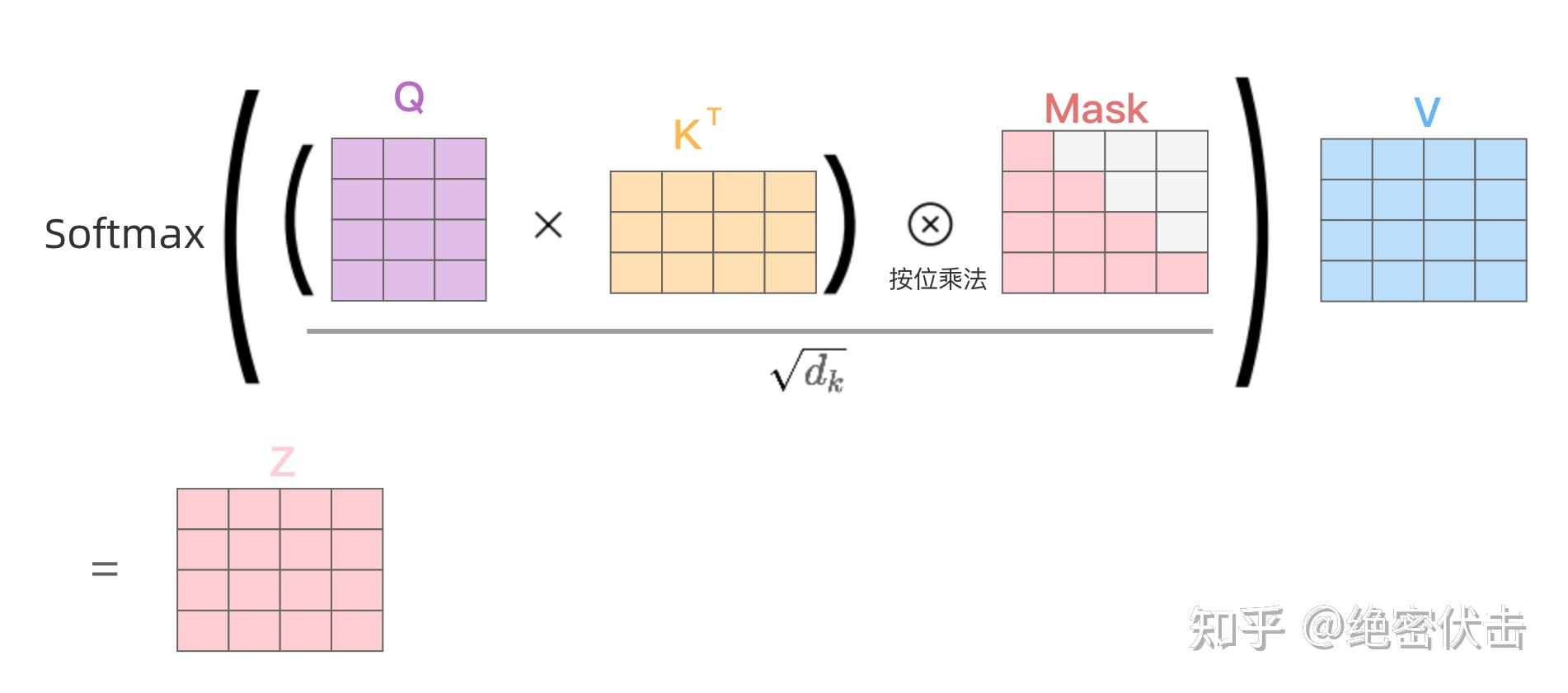
Masked Multi-Head Attention 遮罩多头注意力
我们注意到在Encoder部分的多头注意力机制是没有Masked前缀的,而Decoder部分则存在这一前缀,区别在于编码时编码器同时获取样本的全部Token并对其编码,这个过程是可以完全并行化,没有先后顺序的,在Multi-Head Attention看来一个词的顺序无关紧要(这也是Embedding阶段要加入时序信息的原因),然而在解码阶段,“翻译”这一过程要求顺序进行,即第i个词只能通过前面i-1个词的信息推理得到,而不能有i+1等词的信息干扰
整体流程
Encoder
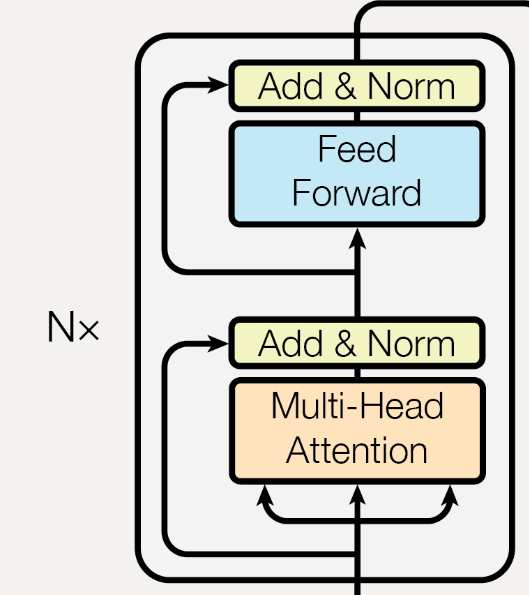
Add & Norm是指残差连接后使用LayerNorm,表示为
其中 Sublayer(x) 是子层(Multi-Head或Feed Forward)本身实现的函数,比如在第一个Add & Norm过程中中Sublayer(x)表示Multi-Head Attention的输出,x是Embedding后的输入矩阵。
Feed Forward指全连接的前馈网络,由两个线性变换组成,中间有一个 ReLU 激活,表示为
Kernel size 为 1 ,输入和输出维数为512,内层维数为2048😊
考虑到使残差连接实现的便捷性,原文在计算的整个过程中矩阵大小都没有改变即,以上为一次Encoder的计算过程,将一次计算的结果作为下一次计算的输入,迭代N次即得到Encoder的最终结果。
Decoder
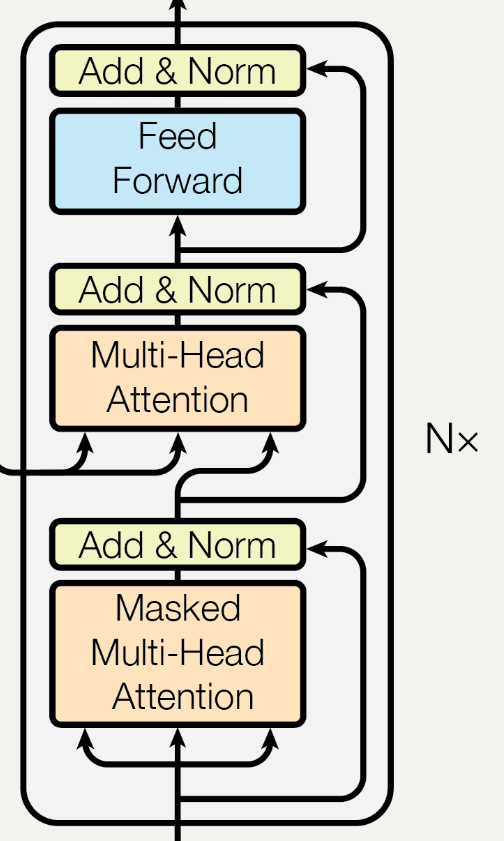
Decoder在去除掉第一个Masked Multi Head子层后与Encoder的结构十分相似,唯一不同的是,在Decoder的第二个子层,即中间的Multi-Head部分,其输入的Q来源于Decoder的第一个子层,而KV来源于Encoder
Decoder也是自回归的,在N次迭代过程中,Decoder的第二个子层,即中间的Multi-Head部分,其输入的KV均来源于Encoder
Linear&Softmax
Decoder的输出是浮点数的向量列表。我们是如何将其变成一个单词的呢?这就是最终的线性层和softmax层所做的工作。
线性层是一个简单的全连接神经网络,它是由Decoder堆栈产生的向量投影到一个更大,更大的向量中,称为对数向量,假设实验中我们的模型从训练数据集上总共学习到1万个英语单词(“Output Vocabulary”)。在线性层计算之后,原向量被降维到1万。
最终的Softmax对降维后的向量做多分类,对应单词表中分值最高的单词被确定为结果,模型在获取到终止符号(


