树状数组
1.应用范围
区别于普通数组的O1更改和On求区间和,前缀和数组的O1求区间和和On更改 树状数组拥有更加均衡的Ologn的求和与更改速度,适合两种情况均大量出现的情景,同时,树状数组可以处理区间更改和查询问题。
树状数组解决的问题线段树都能解决,然而树状数组复杂程度低于线段树。
2.原理介绍
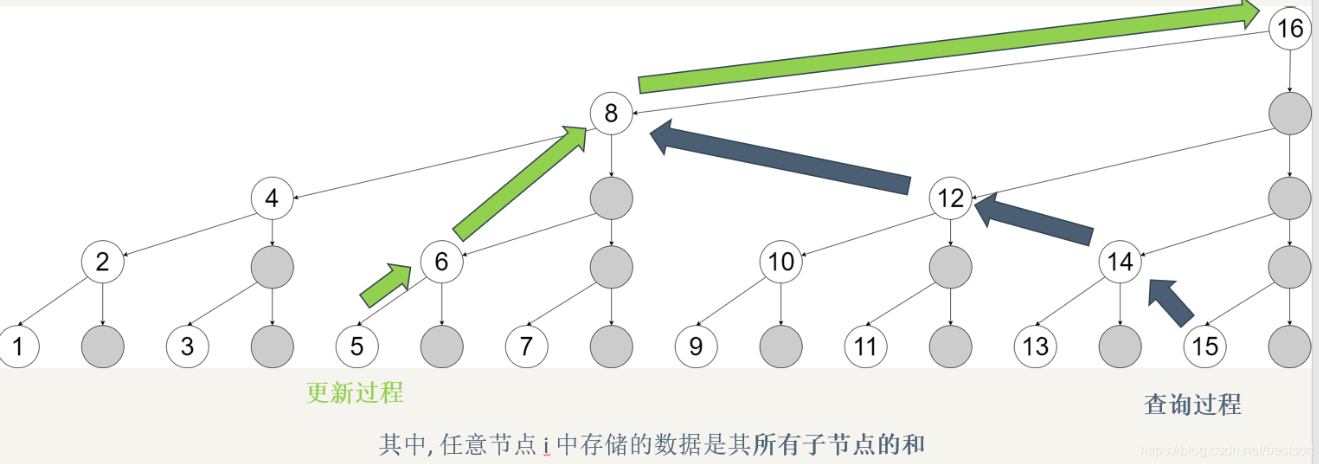
下面是二进制版本,能看到
更新过程是每次加了个二进制的低位1(101+1 ->110, 110 + 10 -> 1000, 1000 + 1000 -> 10000)
查询过程每次就是去掉了二进制中的低位1(1111 - 1 -> 1110, 1110 - 10 -> 1100, 1100 - 100 -> 1000)
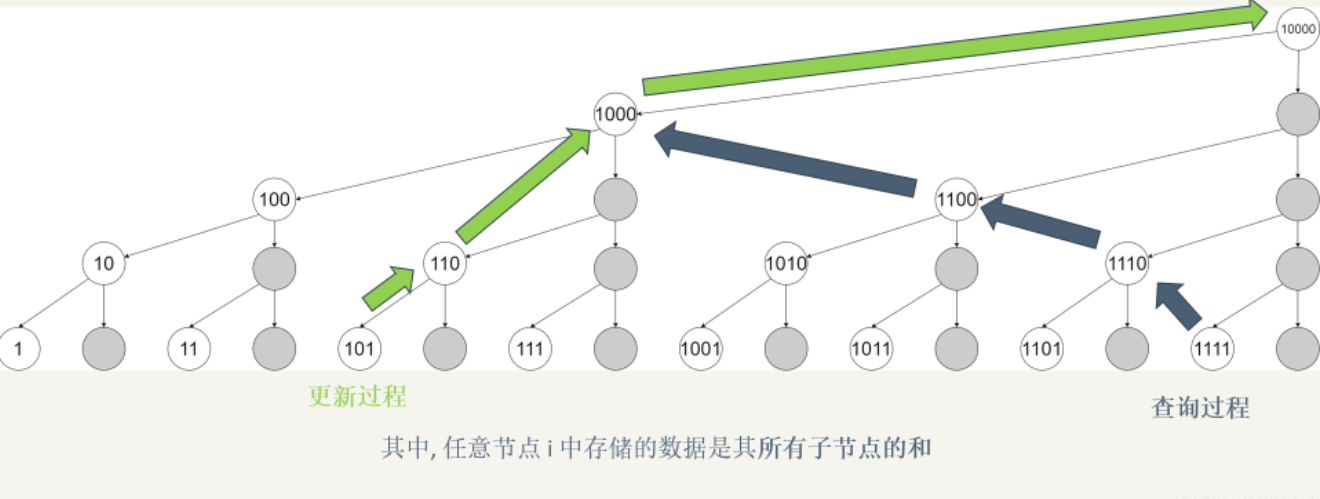
3.低位1的获取
int lowbit(x){return x&(-x);} |
4.单点更新
记原始数组为A,树状数组为C
则如果我们要更改A[1],有以下需要进行同步更新
1(001) C[1]+=A[1]
lowbit(1)=001 1+lowbit(1)=2(010) C[2]+=A[1]
lowbit(2)=010 2+lowbit(2)=4(100) C[4]+=A[1]
lowbit(4)=100 4+lowbit(4)=8(1000) C[8]+=A[1]
换成代码就是:
void update(int x,int y,int n){ |
5.区间查询
区间查询:
举个例子 i=5
C[4]=A[1]+A[2]+A[3]+A[4];
C[5]=A[5];
可以推出: sum(i = 5) ==> C[4]+C[5];
序号写为二进制: sum(101)=C[(100)]+C[(101)];
第一次101,减去最低位的1就是100;
单点更新的逆操作
代码如下:
int getsum(int x){ |
6.例题
class NumArray { |
7.高级应用
区间更新+单点求和
把x-y区间内的所有值全部加上k或者减去k,查询某个点的值
通过“差分”(就是记录数组中每个元素与前一个元素的差),可以把这个问题转化为问题1。

//此时的树状数组是差分形式,即先将原数组差分化,再对该数组树状化 |
区间更新+区间求和
把x-y区间内的所有值全部加上k或者减去k,查询某个区间的和
基于问题2的“差分”思路,考虑一下如何在问题2构建的树状数组中求前缀和:

查询
位置p的前缀和即:(p+1)*[sum1数组中p的前缀和 - sum2数组中p的前缀和]。
区间[l, r]的和即:位置r的前缀和 - 位置l的前缀和。
修改
对于sum1数组的修改同问题2中对d数组的修改。
对于sum2数组的修改也类似,我们给 sum2[l] 加上 l * x,给 sum2[r + 1] 减去 (r + 1) * x。
void add(ll p, ll x){ |
树状数组解决RMQ问题
//树状范围:【x-lowbit(x)+1,x】 |
8.模板题
区间修改、单点查询模板题目:https://www.luogu.org/problem/show?pid=3368
区间修改、区间查询模板题目:https://vjudge.net/problem/POJ-3468
线段树
1.建树
struct SegmentTree{ |
2.单点修改
在线段树中,根节点(编号为1的节点)是执行各种指令的入口。
我们需要从根节点出发,递归找到代表区间[x,x]的叶子节点,然后从下往上更新[x,x]以及它的所有祖先节点上保存的数据信息。
//更新函数,这里是实现最大值 ,同理可以变成,最小值,区间和等 |
3.区间查询
区间查询时一条形如"Q l r"的指令,例如查询序列A在区间[L,R]上的最大值,即m a x L ≤ i ≤ R ( A [ i ] ) max_L\leq i\leq R(A[i])max
L
≤i≤R(A[i])。我们只需要从根节点出发,递归执行以下过程:
若待查询区间[L,R]已经完全覆盖了当前节点所代表的区间,即当前树中的这个节点所代表的区间[t r [ u ] . l tr[u].ltr[u].l,t r [ u ] . r tr[u].rtr[u].r] ⊆ [ L , R ] \subseteq [L,R]⊆[L,R],则立即回溯,并且该节点的val值为候选答案。
若左子节点所代表的区间与待查询区间[L,R]有重叠部分,则递归访问左子节点。
若右子节点所代表的区间与待查询区间[L,R]有重叠部分,则递归访问右子节点。
递归方式区间查询区间[L,R] |
4.*区间修改
为此引入线段树的延迟标记概念,也叫 lazy tag,这个标记一般用于处理线段树的区间更新。
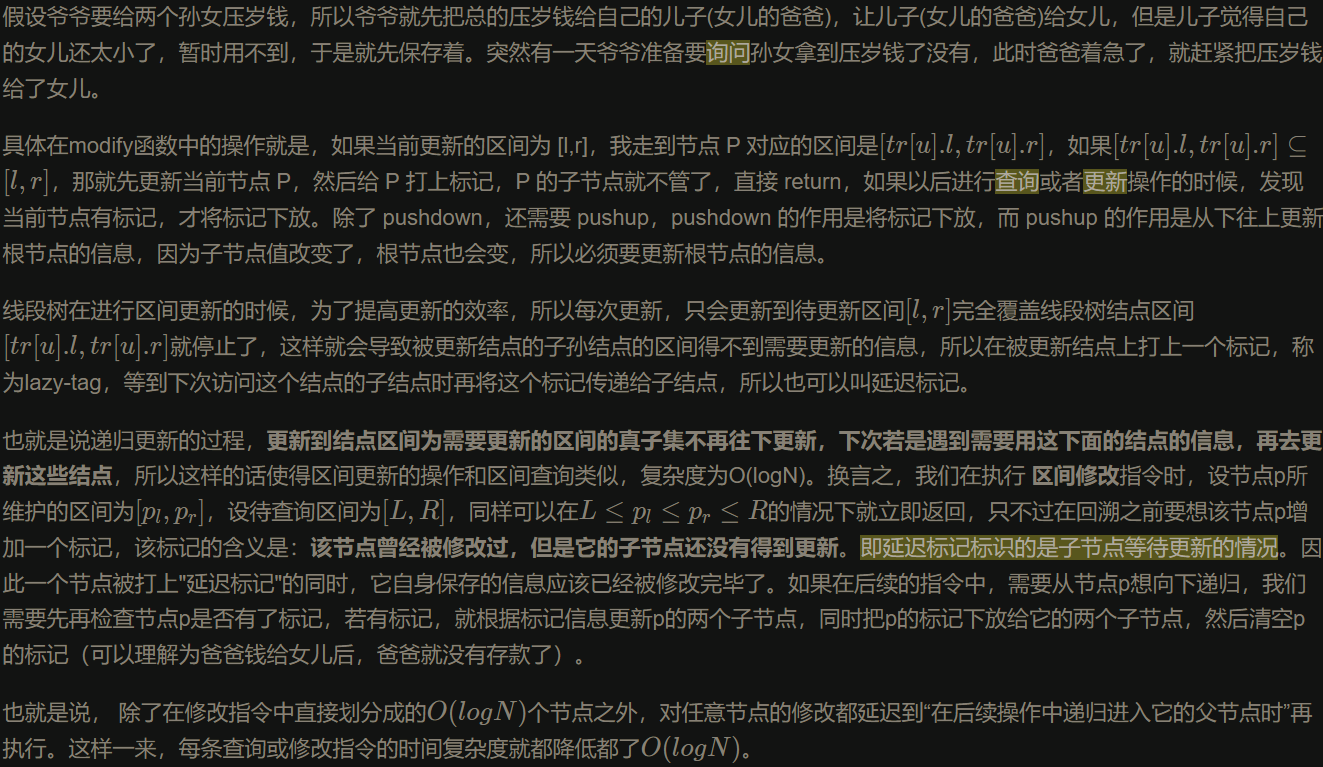
延迟标记:节点结构体中新增一个标记,记录这个节点是否会进行某种修改,对于任意区间的修改,我们先按照区间查询的方式将其划分成线段树中的节点,然后修改这些节点的信息,并给这些节点打上标记。在修改和查询的时候,如果我们到了一个节点 P,并且要继续查看其子节点,那么我们就要看看节点 P 是否被标记,如果有,则需要按照其标记首先修改子节点的信息,并且给子节点都打上相同的标记,同时取消节点 P 的标记,这一操作称为标记下放,也叫 pushdown。举个栗子:
struct NOde{ |
注意看pushdown这个函数,也就是当需要查询某个结点的子树时,需要用到这个函数,函数功能就是更新子树的tag值,可以理解为平时先把事情放着,等到哪天要检查的时候,就临时再去做,而且做也不是一次性做完,检查哪一部分它就只做这一部分。值得注意的是,使用了Lazy_tag后,我们再进行区间查询也需要改变。
5.*注意点
"区间内的最大值"和"区间的累加和"的query函数形式是一样的,设为A;"区间内的最大公约数"和"最大连续子段和"的qeury函数形式是一样的,设为B。但是A和B的形式有所不同
对于A类,与B类的不同点
int query(int u,int L,int R) |
对于B类,与A类的不同点
Node query(int u,int L,int R) |
单点修改函数和区间修改函数也是有不同点的:
单点修改函数:
void modify(int u,int x,int v) |
区间修改函数
void modify(int u,int L,int R,int v) |
RMQ
RMQ(Range Minimum/Maximum Query),即区间最值查询,是指这样一个问题:对于长度为n的数列A,回答若干次询问RMQ(i,j),返回数列A中下标在区间[i,j]中的最小/大值。
本文介绍一种比较高效的ST算法解决这个问题。ST(Sparse Table)算法可以在O(nlogn)时间内进行预处理,然后在O(1)时间内回答每个查询。
1.预处理
设A[i]是要求区间最值的数列,F[i, j]表示从第i个数起连续2^j个数中的最大值。(DP的状态)
例如:
A数列为:3 2 4 5 6 8 1 2 9 7
F[1,0]表示第1个数起,长度为2^0=1的最大值,其实就是3这个数。同理 F[1,1] = max(3,2) = 3, F[1,2]=max(3,2,4,5) = 5,F[1,3] = max(3,2,4,5,6,8,1,2) = 8;
并且我们可以容易的看出F[i,0]就等于A[i]。(DP的初始值)
我们把F[i,j]平均分成两段(因为F[i,j]一定是偶数个数字),从 i 到i + 2 ^ (j - 1) - 1为一段,i + 2 ^ (j - 1)到i + 2 ^ j - 1为一段(长度都为2 ^ (j - 1))。于是我们得到了状态转移方程F[i, j]=max(F[i,j-1], F[i + 2^(j-1),j-1])。
2.查询
假如我们需要查询的区间为(i,j),那么我们需要找到覆盖这个闭区间(左边界取i,右边界取j)的最小幂(可以重复,比如查询1,2,3,4,5,我们可以查询1234和2345)。
因为这个区间的长度为j - i + 1,所以我们可以取k=log2( j - i + 1),则有:RMQ(i, j)=max{F[i , k], F[ j - 2 ^ k + 1, k]}。
举例说明,要求区间[1,5]的最大值,k = log2(5 - 1 + 1)= 2,即求max(F[1, 2],F[5 - 2 ^ 2 + 1, 2])=max(F[1, 2],F[2, 2]);
void ST(int n) {//预处理dp |
差分
一维差分

|
二维差分

|


