|
GCC
查看文件头信息:readelf -h 文件名
查看十六进制数据:
- 完整显示:
xxd 文件名|od -A x -t x1z 文件名 - 部分显示:
od --skip bytes=偏移地址 --read-bytes=字节数 -A x -t x1z 文件名
检索程序导入的函数:objdump -R 文件名
查看程序所有函数及反汇编:objdump -d 文件名
反汇编整个文件:ndisasm -u 文件名
查找ROP:ROPgadget --binary 文件名
过滤ROP:ROPgadget --binary 文件名 --only '指令1|指令2'
运行程序:./文件名
通过python构造payload:python -c 'print "payload"' | ./文件名
将文件内容作为输入:cat payload文件 -| ./文件名
生成字符串队列:cyclic 字符数
计算字符串偏移:cyclic -l 四个字母
连接远程服务器:nc ip地址 port
下载远程目录中的程序:scp -P 端口号 -p IP地址:路径/* ./
自动生成ROP链(若存在),只适用于静态链接程序:ROPgadget --binary 文件名 --ropchain
gcc 与 g++ 分别是 gnu 的 c & c++ 编译器 gcc/g++ 在执行编译工作的时候,总共需要4步:
- 1、预处理,生成 .i 的文件[预处理器cpp]
- 2、将预处理后的文件转换成汇编语言, 生成文件 .s [编译器egcs]
- 3、有汇编变为目标代码(机器代码)生成 .o 的文件[汇编器as]
- 4、连接目标代码, 生成可执行程序 [链接器ld]
-c
只激活预处理,编译,和汇编,也就是他只把程序做成obj文件
例子用法:
gcc -c hello.c |
他将生成 .o 的 obj 文件
-S
只激活预处理和编译,就是指把文件编译成为汇编代码。
例子用法:
gcc -S hello.c |
他将生成 .s 的汇编代码,你可以用文本编辑器察看。
-E
只激活预处理,这个不生成文件, 你需要把它重定向到一个输出文件里面。
例子用法:
gcc -E hello.c > pianoapan.txt |
慢慢看吧, 一个 hello word 也要与处理成800行的代码。
-o
制定目标名称, 默认的时候, gcc 编译出来的文件是 a.out, 很难听, 如果你和我有同感,改掉它, 哈哈。
例子用法:
gcc -o hello.exe hello.c (哦,windows用习惯了) |
-pipe
使用管道代替编译中临时文件, 在使用非 gnu 汇编工具的时候, 可能有些问题。
gcc -pipe -o hello.exe hello.c |
-C
在预处理的时候, 不删除注释信息, 一般和-E使用, 有时候分析程序,用这个很方便的。
-M
生成文件关联的信息。包含目标文件所依赖的所有源代码你可以用 gcc -M hello.c 来测试一下,很简单。
-g
只是编译器,在编译的时候,产生调试信息。
-static
此选项将禁止使用动态库,所以,编译出来的东西,一般都很大,也不需要什么动态连接库,就可以运行。
-share
此选项将尽量使用动态库,所以生成文件比较小,但是需要系统由动态库。
-traditional
试图让编译器支持传统的C语言特性。
一、-g
-g可执行程序包含调试信息
-g为了调试用的
加个-g 是为了gdb 用,不然gdb用不到
二、-o
-o指定输出文件名
-o output_filename,确定输出文件的名称为output_filename,同时这个名称不能和源文件同名。如果不给出这个选项,gcc就给出预设的可执行文件a.out。
一般语法:
gcc filename.c -o filename
上面的意思是如果你不打 -o filename(直接gcc filename.c )
那么默认就是输出a.out.这个-o就是用来控制输出文件的。 ------用./a.out执行文件
三、-c
-c 只编译不链接
产生.o文件,就是obj文件,不产生执行文件
四、-D
其意义是添加宏定义,这个很有用。
当你想要通过宏控制你的程序,不必傻乎乎的在程序里定义,然后需要哪个版本,去修改宏。
只需要在执行gcc的时候,指定-D,后面跟宏的名称即可。
示例:
gcc test.c -o test -D OPEN_PRINTF_DEBUG
或者gcc test.c -o test -DOPEN_PRINTF_DEBUG
两者都是可以的。
五、-w
-w的意思是关闭编译时的警告,也就是编译后不显示任何warning,因为有时在编译之后编译器会显示一些例如数据转换之类的警告,这些警告是我们平时可以忽略的。
六、-W和-Wall
-W选项类似-Wall,会显示警告,但是只显示编译器认为会出现错误的警告。
-Wall选项意思是编译后显示所有警告
七、-O3
-O是大写字母O,不是数字0哦。
意思是开启编译优化,等级为三。
八、-shared
如果想创建一个动态链接库,可以使用 gcc的-shared选项。输入文件可以是源文件、汇编文件或者目标文件。
九、-fPIC
-fPIC 选项作用于编译阶段,告诉编译器产生与位置无关代码(Position-Independent Code)
这样一来,产生的代码中就没有绝对地址了,全部使用相对地址,所以代码可以被加载器加载到内存的任意位置,都可以正确的执行。这正是共享库所要求的,共享库被加载时,在内存的位置不是固定的。
例1:
例2:
-l(小写的l)参数就是用来指定程序要链接的库,-l参数紧接着就是库名,那么库名跟真正的库文件名有什么关系呢?
就拿数学库来说,他的库名是m,他的库文件名是libm.so,很容易看出,把库文件名的头lib和尾.so去掉就是库名了。
好了现在我们知道怎么得到库名了,比如我们自已要用到一个第三方提供的库名字叫libtest.so,那么我们只要把libtest.so拷贝到/usr/lib里,编译时加上-ltest参数,我们就能用上libtest.so库了(当然要用libtest.so库里的函数,我们还需要与libtest.so配套的头文件)。放在/lib和/usr/lib和/usr/local/lib里的库直接用-l参数就能链接了。
但如果库文件没放在这三个目录里,而是放在其他目录里,这时我们只用-l参数的话,链接还是会出错,出错信息大概是:“/usr/bin/ld: cannot find -lxxx”,也就是链接程序ld在那3个目录里找不到libxxx.so,这时另外一个参数-L就派上用场了,比如常用的X11的库,它放在/usr/X11R6/lib目录下,我们编译时就要用-L /usr/X11R6/lib -lX11参数,-L参数跟着的是库文件所在的目录名。再比如我们把libtest.so放在/aaa/bbb/ccc目录下,那链接参数就是-L/aaa/bbb/ccc -ltest
————————————————
版权声明:本文为CSDN博主「幽冥之花」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_30011277/article/details/103711155
GDB
选择文件
gdb 文件名
gdb ; file 文件名
附加进程:attach 进程ID
运行:run
将文件数据作为运行参数:run < file
运行至程序入口:start
单步步入:si
单步步过:ni
在指定函数设置断点:b 函数名
在指定地址设置断点:b *地址
继续运行程序:continue | c
查看所有寄存器的值:reg
查看指定寄存器的值:p $寄存器代号
查看内存布局:i proc mappings
查看内存数据:
以反汇编形式查看数据:x/[字节数]i 地址
以32位十六进制形式查看数据:x/[字节数]wx 地址
以64位十六进制形式查看数据:x/[字节数]gx 地址
查看函数调用情况:backtrace | bt
查看栈数据:stack
查看所有函数定义:i functions
查看指定函数反汇编代码:disassemble 函数名
查看当前函数反汇编代码:disassemble $pc
查看libc动态地址:libc
查找字符串所在地址:search ‘字符串’
————————————————
版权声明:本文为CSDN博主「lzyddf」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_41988448/article/details/103124339
GDB常用的调试命令
一大波命令来袭,hold,或者jump
(gdb)help:查看命令帮助,具体命令查询在gdb中输入help + 命令,简写h
(gdb)run:重新开始运行文件(run-text:加载文本文件,run-bin:加载二进制文件),简写r
(gdb)start:单步执行,运行程序,停在第一执行语句
(gdb)list:查看原代码(list-n,从第n行开始查看代码。list+ 函数名:查看具体函数),简写l
(gdb)set:设置变量的值
(gdb)next:单步调试(逐过程,函数直接执行),简写n
(gdb)step:单步调试(逐语句:跳入自定义函数内部执行),简写s
(gdb)backtrace:查看函数的调用的栈帧和层级关系,简写bt
(gdb)frame:切换函数的栈帧,简写f
(gdb)info:查看函数内部局部变量的数值,简写i
(gdb)finish:结束当前函数,返回到函数调用点
(gdb)continue:继续运行,简写c
(gdb)print:打印值及地址,简写p
(gdb)quit:退出gdb,简写q
(gdb)break+num:在第num行设置断点,简写b
(gdb)info breakpoints:查看当前设置的所有断点
(gdb)delete breakpoints num:删除第num个断点,简写d
(gdb)display:追踪查看具体变量值
(gdb)undisplay:取消追踪观察变量
(gdb)watch:被设置观察点的变量发生修改时,打印显示
(gdb)i watch:显示观察点
(gdb)enable breakpoints:启用断点
(gdb)disable breakpoints:禁用断点
(gdb)x:查看内存x/20xw 显示20个单元,16进制,4字节每单元
(gdb)run argv[1] argv[2]:调试时命令行传参
以上就是GDB的命令其中的部分,下面列详细写一些基础常用的命令:
**list **
list 可写为l,可以列出所调试程序的代码
1.list+linenumber
可以列出linenumber附近的代码
2.list function
可以列出函数上下文的源程序
run&quit
在GDB中如何将程序运行起来,此时只要输入run命令,就可以将命令跑起来
而quit则是退出GDB调试
break

gdb调试时使用break命令来设置断点,有如下几种下断点地方法
break < function >
在进入指定的函数function时既停止运行,C++中可以使用class::function或function(type, type)格式来指定函数名称
break < lineNumber>
在指定的代码行打断点
break +offset/break -offset
在当前行的前面或后面的offset行打断点,offset为自然数
break filename:lineNumber
在名称为filename的文件中的第lineNumber行打断点
break filename:function
在名称为filename的文件中的function函数入口处打断点
break *address
在程序运行的内存地址处打断点
break
在下一条命令处停止运行
break … if < condition>
在处理某些循环体中可使用此方法进行调试,其中…可以是上述的break lineNumber、break +offset/break -offset中的参数,其中condition表示条件,在条件成立时程序即停止运行,如设置break if i=100表示当i为100时程序停止运行。
查看断点时,也可以使用info命令如info breakpoints [n]、info break [n]其中n 表示断点号来查看断点信息。
可以通过delete命令删除所有的断点
next
使用next命令单步执行程序代码,next的单步不会进入函数的内部,与next对应的step命令则在单步执行一个函数时进入函数内部,类似于VC++中的step into.
其用法如下
next <count>
单步跟踪,如果有函数调用不会进入函数,如果后面不加count表示一条一条的执行,加count表示执行后面的count条指令
continue
当程序遇到断点停下来之后,可以执行continue继续执行到下一个断点或到程序结束
print可以缩写为p,可以通过print命令查看参数或程序运行数据
值得注意的是print输出可以指定输出格式:
x按16进制格式显示变量
d按十进制显示变量
u按十六进制格式显示无符号整形
o按八进制格式显示变量
t按二进制格式显示变量
c按字符格式显示变量
f按浮点数格式显示变量
GDB查看,执行汇编语言
查看汇编 disassemble
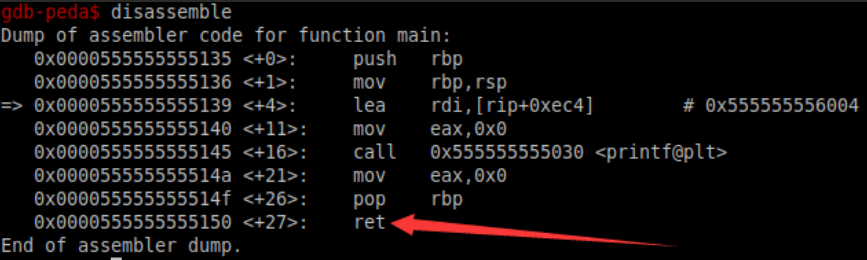
那么我如果要是在红箭头出进行下断如何下?

还有这种随源码一起排列的,是不是很直观:
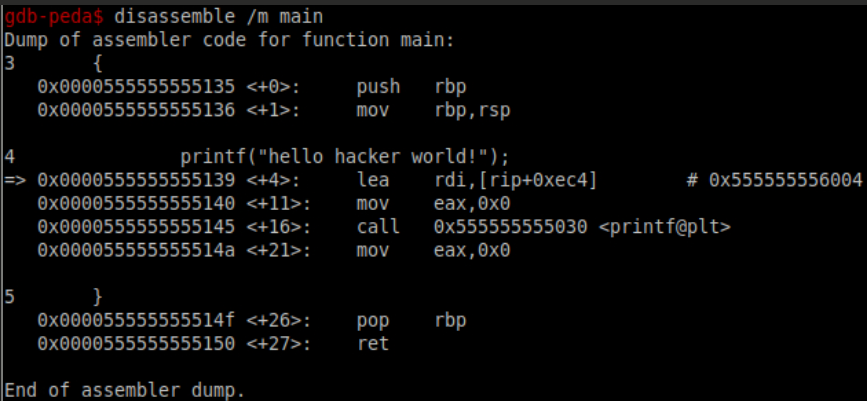
再补充几条命令
backtrace(直译回溯)(bt)
当你的程序调用了一个函数,函数的地址,函数参数,函数内的局部变量都会被压入“栈”(Stack)中。你可以用这条命令来查看当前的栈中的所有信息。人为的将程序下断停住,直接上图:
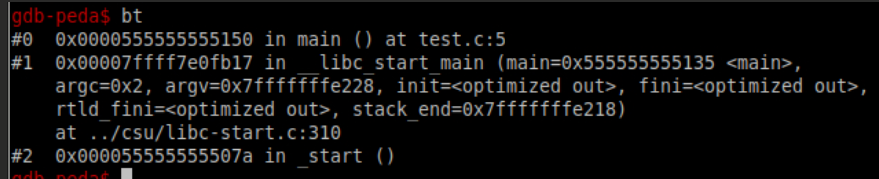
bt n
显示栈顶的几个层的信息
bt -n
显示栈底下的几层信息
but,如果你要查看某一层的信息,你需要在切换当前的栈,一般来说,程序停止时,最顶层的栈就是当前栈,如果你要查看栈下面层的详细信息,首先要做的是切换当前栈。(就有了下面这条命令)
frame(帧)(f)
f
n是一个从0开始的整数,是栈中的层编号。比如:frame 0,表示栈顶,frame 1,表示栈的第二层。
up
表示向栈的上面移动n层,可以不打n,表示向上移动一层。
down
表示向栈的下面移动n层,可以不打n,表示向下移动一层。
info f
会打印出更为详细的当前栈层的信息,只不过,大多数都是运行时的内内
地址
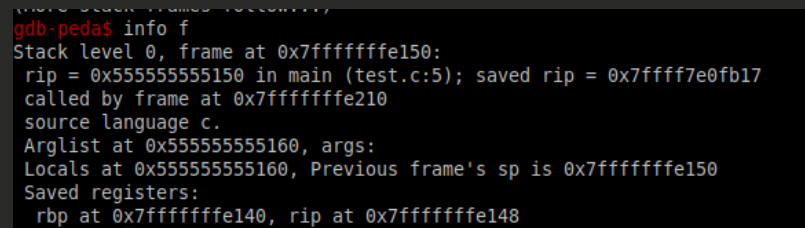
(以下讲解没有截图,为避免审美疲劳,请适度观看)
print(p)
可以输出东西可多,全局变量,静态全局变量,局部变量,如果你的局部变量和全局变量发生冲突(也就是重名),一般情况下是局部变量会隐藏全局变量。
查看全局变量,利用::,例如在1.c中看x
gdb)p “1.c”::x
数组(动
p *array@len
array:数组的首地址,len:数据的长度
(gdb) p *array@len
$1 = {1, 2, 3, 4, 5}
(静)
直接p数组名
所有寄存器的值
info registers
查看指定的寄存器的值
p $eip
结构体
如果你想很漂亮的输出结构体请设置
set print pretty on
打开print pretty这个东西,没错,输出很漂亮滴,
总而言之,p很强大,只要你想输出。
————————————————
版权声明:本文为CSDN博主「whoah」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/awm_kar98/article/details/82840811
pwntools
导入pwntools:from pwn import *
输出调试信息:context.log_level = ‘debug’
设置cpu架构:context.arch = ‘i386’/‘amd64’
远程连接:sh = remote(‘IP’,PORT)
本地运行:sh = process(‘./elf’)
发送数据:sh.send(data)
发送数据,并在末尾加上换行符(\n):sh.sendline(data)
在指定字符出现后输入指定字符串:sh.sendafter(‘等待的字符串’, ‘输入的字符串’)
在指定字符出现后输入指定字符串与回车:sh.sendlineafter(‘等待的字符串’, ‘输入的字符串’)
接收数据,numb指定字节数,timeout指定超时时间:sh.recv(numb=4096, timeout=default)
接收一行数据,keepends表示是否保留行尾的换行符(\n):sh.recvline(keepends=True)
一直接收到字符串delims出现,drop表示是否保留参数1:sh.recvuntil(delims, drop=False)
一直接收数据直到EOF:sh.recvall()
进入shell模式:sh.interactive()
附加gdb调试:gdb.attach(sh)
加载elf文件:elf = ELF(‘[文件名]’)
查看指定函数的PLT地址:function_plt = elf.plt[‘函数名’]
定位字符串静态偏移:elf.search(‘字符串’).next()
将整数转换成32位的小端字节序:p32(整数)
将4个字节转换成最多4字节的整数:u32(字符串.ljust(4, ‘\x00’))
将整数转换成64位的小端字节序:p64(整数)
将8个字节转换成最多8字节的整数:u64(字符串.ljust(8, ‘\x00’))
生成指定字符数量的字符串:str = cyclic(字符数)
查找指定字符串偏移:index = cyclic_find(‘四个字母’)
生成一段shellcode汇编代码:shellcode = shellcraft.sh()
编译shellcode汇编代码为字节码:shellcode = asm(shellcraft.sh())


